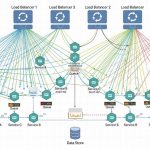
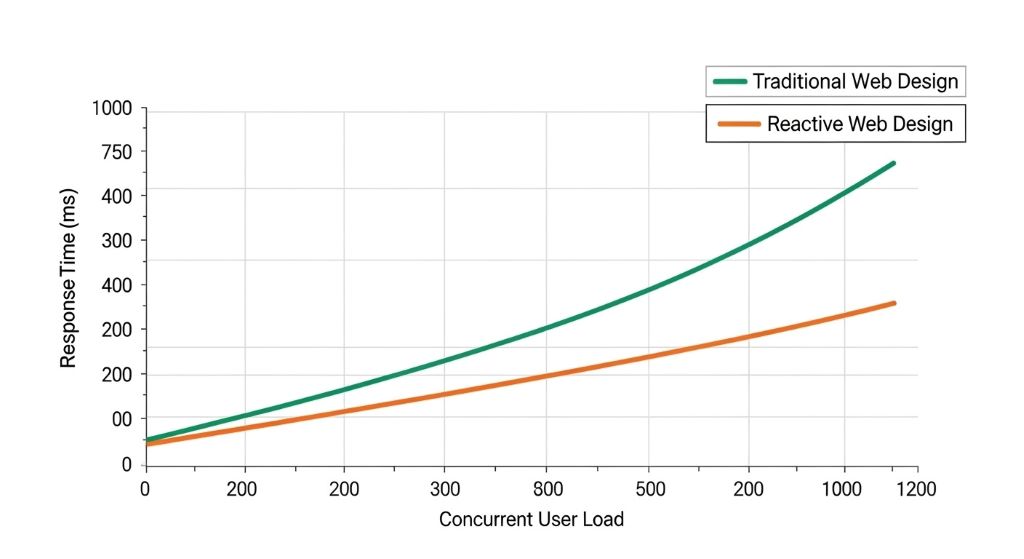
Website performance during traffic surges separates successful online businesses from frustrated users clicking away. Reactive web design offers powerful solutions for maintaining speed and functionality when visitor numbers spike. This architectural approach fundamentally changes how websites handle demand.
Traditional web design struggles under heavy loads, causing slow page loads and server crashes. Reactive design, however, distributes processing efficiently and responds dynamically to changing conditions. Understanding these principles helps developers build resilient websites that thrive during peak traffic periods.
Understanding Reactive Web Design Principles
Reactive web design differs from responsive design, though confusion between these terms is common. Responsive design adapts layouts to different screen sizes. Reactive design focuses on how applications respond to data streams and user interactions in real-time.
The reactive paradigm builds on four core principles: responsiveness, resilience, elasticity, and message-driven architecture. These foundations create systems that handle traffic fluctuations gracefully. Therefore, websites maintain performance regardless of simultaneous user numbers.
Reactive systems process data asynchronously rather than waiting for each operation to complete. This non-blocking approach prevents bottlenecks that slow traditional architectures. Additionally, reactive applications react to events immediately, creating fluid user experiences even under load.
Message-driven communication allows system components to work independently. When one part experiences heavy demand, others continue functioning normally. Moreover, this isolation prevents cascading failures that bring down entire websites.
Implementing Asynchronous Processing for Traffic Management
Asynchronous processing revolutionizes how websites handle multiple concurrent requests. Traditional synchronous systems process one request at a time, creating queues during traffic spikes. Reactive systems process multiple requests simultaneously without waiting.
JavaScript frameworks like React and Vue.js implement reactive patterns on the frontend. These libraries update interface elements efficiently based on data changes. Consequently, users see updates immediately without full page reloads that stress servers.
Backend reactive frameworks like Spring WebFlux and Node.js handle server-side asynchronous operations. These platforms process thousands of concurrent connections with minimal resource consumption. Therefore, servers accommodate more users without additional hardware investments.
Event loops manage asynchronous operations by monitoring completion status continuously. When operations finish, callbacks execute immediately. However, the system never blocks waiting for individual operations, maintaining responsiveness throughout.
Leveraging Non-Blocking I/O Operations
Input/output operations typically create performance bottlenecks during high traffic. Database queries, file reads, and API calls pause traditional applications while waiting for responses. Reactive design eliminates these waits through non-blocking I/O.
Non-blocking operations initiate requests and immediately move to other tasks. When data becomes available, the system processes it without having waited idly. Additionally, this approach maximizes CPU utilization during traffic spikes.
Database connections represent common blocking operations in traditional architectures. Reactive database drivers maintain connection pools that serve multiple requests efficiently. Moreover, these drivers handle query results asynchronously, preventing request queuing.
According to TechCrunch, reactive programming allows applications to handle ten times more concurrent users with the same hardware compared to traditional blocking approaches.
Utilizing Backpressure Mechanisms for Load Control
Backpressure prevents system overload by controlling data flow rates dynamically. When components process data slower than they receive it, backpressure signals upstream sources to slow down. This prevents memory overflow and crashes during traffic surges.
Reactive Streams specification defines standardized backpressure protocols. Publishers produce data while subscribers consume it at sustainable rates. Therefore, fast data sources never overwhelm slow consumers with unmanageable volumes.
Buffering strategies complement backpressure by temporarily storing excess data. Bounded buffers prevent unlimited memory consumption during extreme traffic spikes. Additionally, overflow strategies determine whether to drop old data, reject new data, or fail gracefully.
Implementing backpressure requires coordination between all system components. APIs must communicate consumption capacity to upstream services. Moreover, load balancers should route traffic away from saturated servers toward available capacity.
Optimizing Resource Utilization Through Reactive Streams
Reactive Streams transform how applications process continuous data flows. Traditional batch processing loads entire datasets into memory before processing. Reactive streams process data items individually as they arrive.
This streaming approach reduces memory footprint dramatically during heavy traffic. Applications never hold more data than immediately needed. Consequently, servers handle larger total data volumes without memory exhaustion.
Stream processing enables real-time analytics and monitoring during traffic events. Websites track user behavior patterns as they happen rather than through delayed batch reports. Therefore, administrators detect and respond to issues immediately.
Operators transform, filter, and combine streams without blocking execution. Map operations modify data items in flight. Filter operations remove unnecessary items before they consume resources. Additionally, merge operations combine multiple data sources efficiently.
Implementing Caching Strategies in Reactive Architectures
Caching reduces server load by storing frequently requested data in fast-access memory. Reactive applications implement intelligent caching that updates automatically when underlying data changes. This eliminates stale cache problems plaguing traditional systems.
Distributed caching systems like Redis and Memcached integrate seamlessly with reactive architectures. These tools cache database query results, API responses, and rendered page fragments. Moreover, cache invalidation occurs reactively when source data updates.
Edge caching places content geographically closer to users through content delivery networks. Reactive applications push updates to edge servers immediately when content changes. Therefore, users worldwide access fresh content quickly without overwhelming origin servers.
Client-side caching stores data in browser memory and local storage. Progressive web applications cache entire interfaces locally, functioning even during server outages. Additionally, service workers intercept network requests, serving cached content when available.
Scaling Horizontally with Reactive Microservices
Microservices architecture divides applications into independent services communicating through APIs. Reactive microservices handle traffic surges by scaling individual components independently. This targeted scaling proves more efficient than scaling entire monolithic applications.
Container orchestration platforms like Kubernetes automatically scale reactive microservices based on demand. When traffic increases, additional container instances deploy automatically. Conversely, instances shut down during low traffic periods, reducing costs.
Service mesh technologies manage communication between microservices reactively. These tools handle load balancing, retry logic, and circuit breaking automatically. Therefore, failures in individual services don’t cascade through entire systems.
Event-driven communication between microservices maintains loose coupling essential for reactive systems. Services publish events to message brokers rather than calling each other directly. Additionally, this approach enables services to process events at their own pace.
Monitoring and Observability in Reactive Systems
Real-time monitoring becomes crucial when reactive systems handle traffic surges. Traditional monitoring tools often miss the rapid state changes occurring in reactive applications. Therefore, specialized observability solutions track reactive system behavior effectively.
Distributed tracing follows individual requests across multiple microservices and system components. Tools like Jaeger and Zipkin visualize request flows, identifying bottlenecks during traffic spikes. Moreover, these insights guide optimization efforts precisely.
Metrics collection must handle high-frequency data points without impacting application performance. Reactive monitoring systems aggregate metrics asynchronously, preventing measurement overhead. Additionally, time-series databases store metrics efficiently for historical analysis.
According to The New Stack, reactive systems require fundamentally different monitoring approaches because traditional metrics often fail to capture the dynamic nature of asynchronous processing.
Error Handling and Resilience Patterns
Reactive systems implement sophisticated error handling preventing complete failures during traffic surges. Circuit breaker patterns detect failing services and route traffic elsewhere automatically. This prevents overwhelming struggling components with additional requests.
Retry logic attempts failed operations with exponential backoff delays. This gives temporarily unavailable services time to recover without constant retry storms. However, maximum retry limits prevent infinite retry loops consuming resources.
Fallback mechanisms provide degraded functionality when primary systems fail. For example, websites might serve cached content when databases become unavailable. Therefore, users receive some service rather than complete failures.
Bulkhead patterns isolate resources for different operations preventing resource exhaustion. Like ship bulkheads containing water leaks, these patterns prevent failures in one area affecting others. Additionally, dedicated thread pools for critical operations ensure availability.
Database Integration with Reactive Repositories
Traditional database operations block threads while waiting for query results. Reactive database drivers eliminate blocking through asynchronous query execution. This allows applications to handle thousands of concurrent database operations efficiently.
R2DBC provides reactive relational database connectivity for SQL databases. This specification enables non-blocking database access with popular databases like PostgreSQL and MySQL. Moreover, reactive repositories integrate seamlessly with reactive frameworks.
NoSQL databases like MongoDB and Cassandra offer native reactive drivers. These databases handle high write volumes during traffic spikes better than traditional relational databases. Additionally, their distributed nature enables horizontal scaling.
Connection pooling becomes even more critical in reactive applications. Reactive connection pools manage database connections efficiently across many concurrent operations. Therefore, applications maintain database performance without connection exhaustion.
Load Balancing Strategies for Reactive Applications
Intelligent load balancing distributes traffic across server instances optimally. Reactive load balancers monitor instance health and capacity in real-time. This enables dynamic traffic distribution based on current conditions rather than static configurations.
Round-robin algorithms distribute requests evenly across available servers. However, weighted algorithms account for varying server capacities and current loads. Therefore, more powerful servers receive proportionally more traffic.
Session affinity ensures users consistently connect to the same server instance. This proves important for applications maintaining session state. Additionally, sticky sessions reduce cache misses improving response times.
Geographic load balancing routes users to nearest data centers reducing latency. Content delivery networks implement this automatically for static content. Moreover, reactive applications can extend geographic routing to dynamic content through edge computing.
Testing Reactive Applications Under Load
Load testing validates reactive application performance before production deployment. Simulation tools generate realistic traffic patterns including sudden spikes. Therefore, developers identify bottlenecks and capacity limits safely.
Apache JMeter and Gatling create configurable load scenarios testing various traffic conditions. These tools measure response times, throughput, and error rates under different loads. Additionally, they identify the breaking points where performance degrades.
Chaos engineering intentionally introduces failures testing resilience mechanisms. Tools like Chaos Monkey randomly terminate services during load tests. Moreover, this validates that circuit breakers and fallback mechanisms function correctly.
Continuous load testing in staging environments catches performance regressions early. Automated tests run with each code change verifying performance impacts. Therefore, teams maintain performance standards throughout development.
Conclusion
Reactive web design fundamentally improves performance under heavy traffic through asynchronous processing, intelligent resource management, and resilient architecture patterns. The principles of responsiveness, elasticity, and message-driven communication create systems that scale efficiently during demand surges. Additionally, implementing backpressure mechanisms, strategic caching, and microservices architecture enables applications to handle traffic spikes gracefully. Therefore, organizations investing in reactive design principles build websites that maintain excellent user experiences regardless of traffic volumes. The combination of non-blocking operations, distributed processing, and comprehensive monitoring creates robust systems ready for modern web traffic demands.
Frequently Asked Questions
What is the main difference between reactive and responsive web design?
Responsive web design adapts page layouts to different screen sizes and devices. Reactive web design focuses on how applications handle data streams and user interactions asynchronously under varying loads. Both improve user experience but address completely different technical challenges.
Does reactive design require completely rewriting existing websites?
Not necessarily. Teams can implement reactive principles incrementally by refactoring performance bottlenecks first. Start with asynchronous database operations and non-blocking I/O, then gradually introduce reactive frameworks. However, maximum benefits come from comprehensive reactive architectures.
How much traffic increase can reactive design handle?
Properly implemented reactive systems typically handle five to ten times more concurrent users than equivalent traditional architectures. Actual improvements depend on specific implementation details, hardware resources, and application complexity. Load testing determines precise capacity for individual applications.
What programming languages support reactive web design?
Most modern languages support reactive programming through libraries and frameworks. JavaScript, Java, Kotlin, Scala, C#, Python, and Go all offer mature reactive frameworks. Additionally, reactive principles apply across technology stacks through standardized protocols like Reactive Streams.
Is reactive web design more expensive to implement?
Initial development costs may increase slightly due to architectural complexity and developer training needs. However, reactive systems often reduce long-term infrastructure costs through efficient resource utilization. Additionally, reduced downtime during traffic spikes provides significant business value offsetting development investments.
Related Topics:
Why you should consider off page link building for website